
Una delle principali novità introdotte dal Reg. UE 679/2016 “General Data Protection Regulation” (GDPR) è sicuramente l’approccio basato sul risk based thinking. Con l’entrata in vigore in Italia del GDPR abbiamo assistito all’abrogazione del disciplinare tecnico in materia di misure minime per la sicurezza (Allegato B al vecchio D.lgs. 196/2003) che recava una serie di misure di sicurezza standard per la protezione dei dati personali. Se da un lato l’Allegato B agevolava i titolari del trattamento dettando loro gli accorgimenti minimi da adottare, dall’altro spesso si dimostrava inadeguato, poiché la scelta delle misure di sicurezza prescindeva contesto di riferimento. La riforma introdotta dal GDPR si armonizza perfettamente con il principio di accountability: si richiede, infatti, a ciascun titolare del trattamento di valutare nel proprio ambito di riferimento l’analisi del rischio privacy correlato al trattamento dei dati personali e la compliance con il GDPR, quindi di individuare in relazione ad esso le misure di sicurezza più opportune.
Ma come si esegue un’analisi del rischio?
Si espone di seguito un framework semplificato per l’implementazione dell’analisi del rischio che funga da supporto alle organizzazioni:
- nell’identificazione dei propri processi critici dal punto di vista del trattamento dei dati personali;
- nella comprensione e valutazione dei rischi più rilevanti dal punto di vista della sicurezza.
L’approccio adottato prende spunto dagli standard ISO 31000, 27001 e 27701 e dalle linee guida ENISA.
Definire una metodologia di analisi del rischio
L’analisi del rischio, in linea generale, è un processo di valutazione volto a:
- assicurare la possibilità di raggiungere gli obiettivi stabiliti;
- incoraggiare una gestione proattiva;
- prevenire o ridurre gli effetti indesiderati di una determinata attività;
- migliorare i controlli e le misure di sicurezza;
- pianificare le azioni necessarie a perseguire il miglioramento continuo.
Per impostare correttamente il processo l’organizzazione deve, in primo luogo, stabilire una metodologia di analisi volta ad assicurare che ripetute analisi del rischio producano risultati coerenti, validi e confrontabili tra loro. Occorre infatti considerare che l’analisi del rischio non è un’operazione da compiere una tantum, ma un processo continuo che necessita di revisione in occasione di ogni cambiamento significativo (ad esempio modifica di trattamenti, introduzione di nuovi trattamenti ecc.) e almeno una volta l’anno.
Andremo quindi a delineare nei prossimi paragrafi gli step necessari alla definizione di una metodologia efficace di analisi del rischio.
Step 1: Individuare il contesto di riferimento
L’efficacia dell’analisi del rischio dipende in buona parte dalla comprensione del contesto in cui opera un’azienda. È evidente che un data center non avrà le stesse esigenze né di un ospedale, né di una piccola azienda manifatturiera.
Diventa quindi essenziale individuare quali sono i fattori interni ed esterni che incidono a livello strategico e operativo con la propria attività, poiché da questi dipendono i rischi che la stessa si troverà a dover affrontare.
La valutazione del contesto esterno può tenere in considerazione, per esempio, questi fattori:
- l’ambiente sociale, cogente, finanziario, tecnologico, economico, naturale e competitivo, a livello internazionale, nazionale, regionale o locale;
- gli elementi determinanti e le tendenze fondamentali che hanno un impatto sugli obiettivi dell’organizzazione;
- le relazioni con le parti interessate esterne, le loro percezioni e i loro valori.
Per quanto riguarda il contesto interno, invece, è opportuno tener conto:
- della governance, della struttura organizzativa, dei ruoli e delle responsabilità;
- delle politiche, degli obiettivi e delle strategie in atto per il loro conseguimento;
- delle capacità, intese in termini di risorse e conoscenza (per esempio capitale, tempo, persone, processi, sistemi e tecnologie);
- dei sistemi e flussi informativi, dei processi decisionali;
- delle relazioni con i portatori d’interesse interni, delle loro percezioni e valori;
- della cultura dell’organizzazione;
- delle norme, linee guida e modelli adottati dall’organizzazione;
- della forma e dell’estensione delle relazioni contrattuali.
Step 2: Individuare le operazioni di trattamento di dati personali
Una volta determinato il contesto interno ed esterno, l’organizzazione deve mappare le diverse tipologie di trattamento di dati personali.
Per trattamento, ai sensi dell’art. 4 GDPR, si intende “qualsiasi operazione o insieme di operazioni, compiute con o senza l’ausilio di processi automatizzati e applicate a dati personali o insiemi di dati personali, come la raccolta, la registrazione, l’organizzazione, la strutturazione, la conservazione, l’adattamento o la modifica, l’estrazione, la consultazione, l’uso, la comunicazione mediante trasmissione, diffusione o qualsiasi altra forma di messa a disposizione, il raffronto o l’interconnessione, la limitazione, la cancellazione o la distruzione”.
Per individuare i trattamenti è utile domandarsi:
- che tipologie di dati personali vengono trattati?
- quali sono le finalità del trattamento?
- quali mezzi vengono utilizzati per il trattamento?
- dove viene effettuato il trattamento?
- quali sono le categorie di interessati al trattamento?
- dove sono conservati i dati?
Ovviamente, qualora l’azienda disponga di un registro dei trattamenti si potrà avvalere di questo strumento per la mappatura.
Step 3: Classificare i fattori che determinano il rischio privacy
Il rischio è il prodotto tra l’impatto di un determinato evento e la probabilità che esso accada.
R=P*I
Per calcolare il rischio è necessario, in via preliminare, classificare i fattori che lo determinano e quindi l’impatto (I) e la probabilità (P).
Per quanto riguarda le tipologie di impatto da considerare per la salvaguardia dei dati personali è buona prassi far riferimento al paradigma R.I.D della ISO 27001: un’informazione (e quindi anche un dato personale) può dirsi sicura quando è integra, disponibile e riservata.
L’organizzazione dovrà perciò classificare gli impatti definendo una scala di gravità (alta, media o bassa) che tenga in considerazione:
- la criticità dei dati personali coinvolti;
- i requisiti legali/normativi e gli obblighi contrattuali;
- l’importanza di business ed operativa in merito alla disponibilità, riservatezza ed integrità;
- i diritti e le libertà degli interessati.
Di seguito si propone una possibile classificazione.
Impatto dovuto alla perdita di integrità:
| Tipo | Valore | Descrizione |
| Basso | 1 | I dati non presentano particolari requisiti di integrità. La perdita di integrità non ha conseguenze sui diritti e le libertà degli interessati. |
| Medio | 2 | La mancanza di integrità non ha elevati impatti sulle attività operative o sul rispetto della normativa vigente. |
| Alto | 3 | La mancanza di integrità dei dati ha elevati impatti sul business dell’organizzazione, sull’immagine e sul rispetto della normativa vigente e la loro compromissione è tale da ledere i diritti e le libertà delle persone fisiche e l’operatività dell’organizzazione. |
Impatto dovuto alla perdita di disponibilità:
| Tipo | Valore | Descrizione |
| Basso | 1 | L’indisponibilità dei dati oltre i tempi stabiliti contrattualmente non comporta multe o penali rilevanti. I dati possono essere facilmente recuperati o acquisiti. I diritti e le libertà degli interessati sono preservati integri. |
| Medio | 2 | L’indisponibilità dei dati oltre i tempi stabiliti contrattualmente comporta multe o penali non particolarmente rilevanti. Il recupero o la nuova acquisizione dei dati non compromette l’operatività dell’organizzazione. |
| Alto | 3 | L’indisponibilità dei dati oltre i tempi stabiliti contrattualmente comporta multe o penali che mettono in pericolo la sostenibilità economica o l’immagine dell’organizzazione o hanno impatto sui diritti e le libertà di persone fisiche. |
Impatto dovuto alla perdita di riservatezza:
| Tipo | Valore | Descrizione |
| Basso | 1 | I dati non presentano particolari requisiti di riservatezza. I dati sono pubblici. Una loro eventuale diffusione non recherebbe nocumento all’organizzazione e agli interessati. |
| Medio | 2 | I dati devono essere riservati per ragioni di business. Una loro eventuale diffusione non ha elevati impatti sull’attività dell’organizzazione, sul rispetto della normativa vigente e sull’immagine dell’organizzazione. |
| Alto | 3 | La diffusione delle informazioni ha elevati impatti sul business dell’organizzazione, sull’immagine e sul rispetto della normativa vigente tali da compromettere l’operatività dell’organizzazione e i diritti e le libertà degli interessati. |
L’impatto viene valutato separatamente per la riservatezza, l’integrità e la disponibilità dei dati. Il più alto di tali livelli è poi considerato come il risultato della valutazione dell’impatto, relativa al trattamento complessivo dei dati personali.
La stessa operazione di classificazione deve essere fatta per il fattore “probabilità”.
In relazione ad esso non esistono dei dati oggettivi: ciascuna organizzazione dovrà tener conto del proprio storico.
Si propone un esempio di seguito.
Probabilità di accadimento:
| Tipo | Valore | Descrizione |
| Bassa | 1 | La probabilità è bassa quando il verificarsi dell’evento è un fatto che suscita sorpresa. Non sono noti episodi in cui l’evento si sia verificato. L’evento potrebbe accadere al massimo una volta l’anno. |
| Media | 2 | La probabilità è media quando è noto qualche episodio in cui si è verificato l’evento. L’evento potrebbe capitare da 2 a 3 volte l’anno. |
| Alta | 3 | La probabilità è alta quando si sono già verificati più volte eventi analoghi in azienda. L’evento potrebbe capitare più di 3 volte l’anno. |
Considerato che un’attività non può mai essere a rischio zero, l’azienda può accettare di continuare un’attività senza porre in essere misure di sicurezza ulteriori quando il rischio è basso.
Con i parametri sopra proposti, la situazione tipica di accettazione del rischio può essere raffigurata come segue:
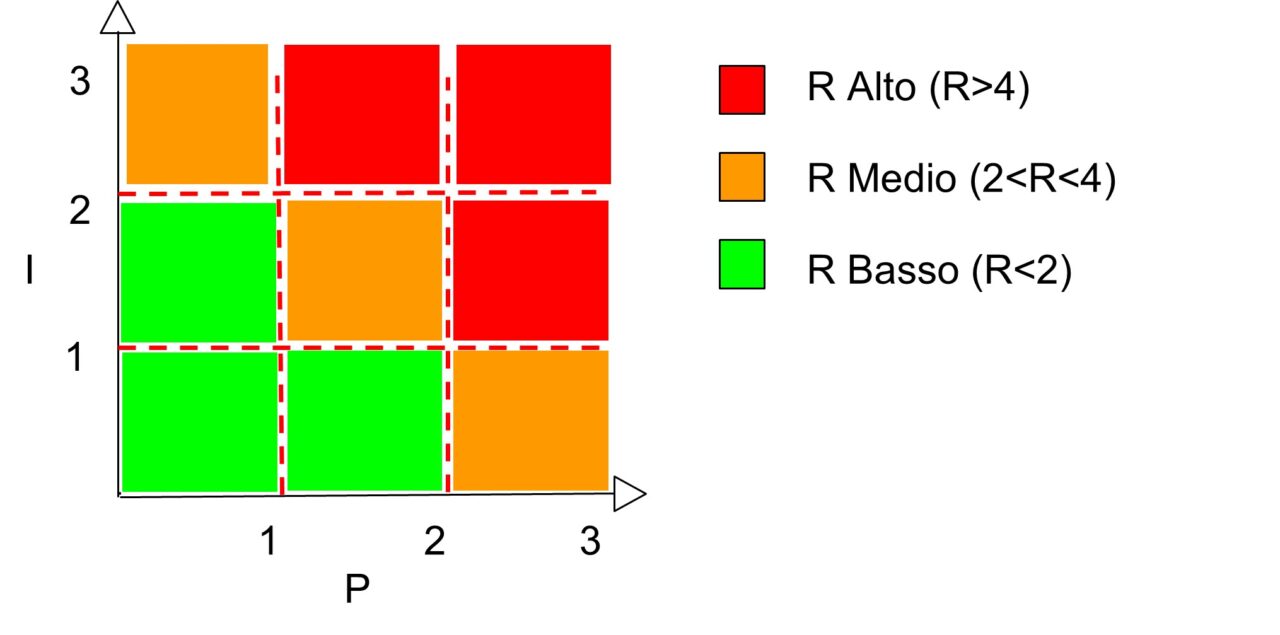
Step 4: Calcolare il rischio privacy
Giunta a questo punto, l’organizzazione deve determinare, tenendo conto del proprio contesto e delle misure di sicurezza già implementate, quali siano gli scenari di rischio possibili, ovvero le minacce interne ed esterne che possono verificarsi.
Un efficace metodo per questa operazione viene suggerito da ENISA (in “Online platform for Security of personal data processing”) che propone anzitutto di individuare quattro macroaree di indagine:
- risorse di rete e tecniche (hardware e software);
- processi / procedure relativi all’operazione di trattamento dei dati;
- diverse parti e persone coinvolte nell’operazione di trattamento;
- settore di attività e scala del trattamento.
Per ciascuna delle aree individuate propone poi di valutare i seguenti scenari di rischio:
| A. Risorse di rete e tecniche (hardware e software) |
| 1. Il trattamento dei dati personali viene effettuato on line? |
| 2. È possibile fornire l’accesso ad un sistema interno di trattamento dei dati personali tramite connessione in rete (ad es. per determinati utenti o gruppi di utenti)? |
| 3. Il sistema di trattamento dei dati personali è interconnesso con un altro sistema esterno o interno o servizio IT? |
| 4. Le persone non autorizzate possono accedere facilmente all’ambiente di elaborazione dei dati? |
| 5. Il sistema di elaborazione dei dati personali è progettato, implementato o mantenuto senza tener conto delle best practices di riferimento? |
| B. Processi / procedure relativi all’operazione di trattamento dei dati |
| 6. I ruoli e le responsabilità in relazione al trattamento dei dati personali sono vaghi, non chiari o non definiti? |
| 7. L’uso accettabile della rete, del sistema e delle risorse fisiche all’interno dell’organizzazione è ambiguo o non chiaramente definito? |
| 8. I dipendenti sono autorizzati a portare e utilizzare i propri dispositivi per connettersi ai sistemi aziendali? |
| 9. I dipendenti sono autorizzati a trasferire, archiviare o altrimenti elaborare dati personali al di fuori della sede dell’organizzazione? |
| 10. È possibile svolgere attività di trattamento dei dati personali senza creare file di log? |
| C. Altre parti coinvolte nell’operazione di trattamento |
| 11. Il trattamento dei dati personali viene eseguito da un numero di dipendenti non definito? |
| 12. Alcune operazioni di trattamento di dati personali sono demandate a persone/enti esterni all’organizzazione (responsabili del trattamento)? |
| 13. Gli obblighi delle parti / persone coinvolte nel trattamento dei dati personali sono ambigui o non chiaramente definiti? |
| 14. Il personale coinvolto nel trattamento dei dati personali non ha familiarità con la sicurezza delle informazioni? |
| 15. Le persone / parti coinvolte nell’operazione di trattamento dei dati trascurano di archiviare in modo sicuro e / o distruggere i dati personali? |
| D. Settore di attività e scala del trattamento |
| 16. Il settore della tua attività soggetto ad attacchi informatici? |
| 17. La tua organizzazione ha subito attacchi informatici o altri tipi di violazione della sicurezza negli ultimi due anni? |
| 18. Hai ricevuto notifiche e / o reclami riguardo alla sicurezza del sistema IT (utilizzato per il trattamento dei dati personali) nell’ultimo anno? |
| 19. Un’operazione di trattamento riguarda un grande volume di persone e / o dati personali? |
| 20. Esistono best practice di sicurezza specifiche per il tuo settore di attività che non sono state utilizzate adeguatamente? |
Per ciascuno degli scenari di rischio sopra esposti ed in relazione a ciascun trattamento eseguito l’azienda dovrà calcolare il rischio secondo la formula R=P*I.
Esempio 1.
Settore: azienda tessile.
Trattamento: trattamento dati fornitori.
Tipologia di dati: dati anagrafici comuni (nome, cognome, piva/c.f., indirizzo, dati di contatto) dati bancari (iban).
Scenario di rischio indagato: 1. Il trattamento dei dati personali viene effettuato online?
Risposta: si.
Calcolo del rischio:
| Tipo impatto | Valore impatto | Probabilità | Rischio (R=P*I) |
| Riservatezza | 1 | 1 | R=1*2 R=2 |
| Integrità | 2 | ||
| Disponibilità | 1 |
Esempio 2.
Azienda: azienda di profilazione dati.
Trattamento: profilazione preferenze utenti TV a pagamento.
Tipologia di dati: dati anagrafici comuni (nome, cognome, età, indirizzo, dati di contatto) dati di profilazione (tipologia di programmi visualizzati, orari di connessione, durata della connessione, tipologia di dispositivo connesso, ricerche frequenti).
Scenario di rischio indagato: 19. Un’operazione di trattamento riguarda un grande volume di persone e / o dati personali?
Risposta: si.
Calcolo del rischio:
| Tipo impatto | Valore impatto | Probabilità | Rischio (R=P*I) |
| Riservatezza | 3 | 2 | R=2*3 R=6 |
| Integrità | 2 | ||
| Disponibilità | 2 |
Step 5: Individuare le attività di trattamento
Come sopra accennato, il rischio può essere accettato dall’azienda quando è basso.
Nelle altre ipotesi (rischio medio o alto) l’azienda può scegliere di:
- modificare il rischio: adottare delle misure di sicurezza ulteriori e appropriate che contribuiscano ad abbassare il livello di rischio. In questo caso, le misure adottate andranno monitorate nel tempo per valutarne l’efficacia;
- condividere il rischio: tale operazione si può effettuare, ad esempio, affidando il trattamento ad un fornitore esterno che offra idonee garanzie per la sicurezza dei dati;
- evitare il rischio: interrompere il trattamento (questa scelta, ovviamente, incide in maniera considerevole sull’attività dell’azienda).
Tendenzialmente l’attività di trattamento maggiormente selezionata è quella di modifica del rischio. La scelta delle misure di sicurezza deve essere ponderata (dati i costi in termini monetari e di tempo) e adeguata alle effettive esigenze.
Le misure di sicurezza possono essere raggruppate in due macro famiglie: misure di tipo organizzativo (ad esempio: politiche per la gestione dei dati o per l’uso dei dispositivi, formazione, responsabilizzazione, controllo della catena di fornitura ecc.) e misure di tipo tecnico (controlli sulla rete, manutenzione dei sistemi, controllo degli accessi fisici e logici, protezioni dai malware, test sui backup ecc.).
Un valido supporto per la scelta delle misure più adeguate può essere fornito dall’Annex A della norma ISO 27001 (controlli per la sicurezza delle informazioni) e dalla recentissima norma ISO 27701 recante i controlli aggiuntivi (rispetto alla ISO 27001) per la sicurezza dei dati personali.
Step 6: Approvare l’analisi del rischio privacy
L’analisi del rischio deve infine essere approvata formalmente dalla direzione, che deve essere sempre cosciente delle possibili minacce per potervi far fronte.
L’approvazione da parte della direzione non è solo una formalità, ma anche da strumento a supporto dell’accountability del titolare del trattamento.
D’altronde, ignorare i rischi è il rischio più grande!























