La gestione della sicurezza del supporto digitale, anche nell’ambito delle esigenze evolutive che tengano conto sia delle possibilità connesse a nuovi modelli organizzativi e a nuove tecnologie, sia delle normative sempre più precise e stringenti, si deve necessariamente basare su un approccio multi-dimensionale -tipico dell’ Health Technology Assessment[1],[2],[3] che tenga conto di tutte le caratteristiche (organizzative, informative, funzionali e tecnologiche) del contesto digitale e di come tali caratteristiche incidano sui fattori di rischio, come schematizzato in figura 1.
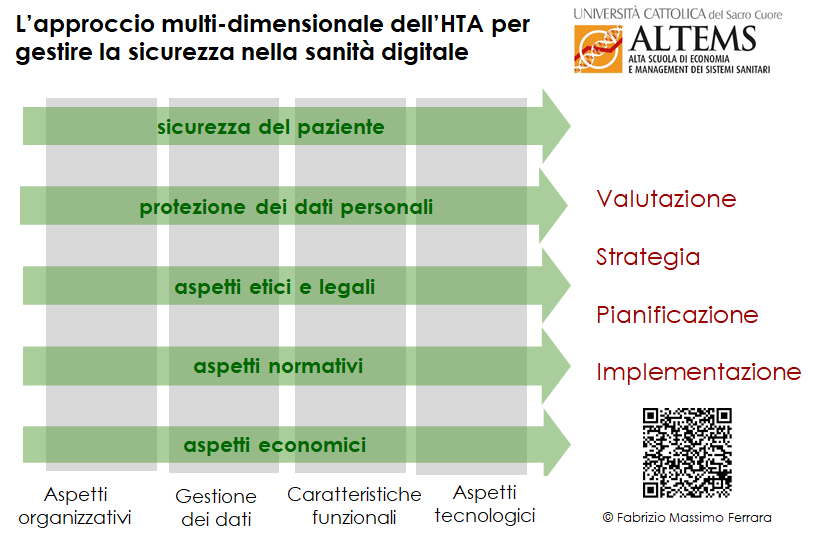
Figura 1 – La sicurezza nella sanità digitale ha una prospettiva multidimensionale
In questo quadro complessivo, un ruolo sicuramente centrale ai fini della prevenzione del rischio clinico è rivestito dagli aspetti inerenti alla gestione dei dati, che -sebbene raccolti attraverso applicazioni, contesti e dispositivi anche eterogenei- devono (figura 2):,
- essere disponibili nel loro complesso dove, quando e come necessario alle persone autorizzate;
- fornire un contributo attivo nell’identificazione di rischi e situazioni di allarme, anche correlando autonomamente informazioni diverse, anche nel caso di co-morbilità e dimenticanze da parte dell’utente.
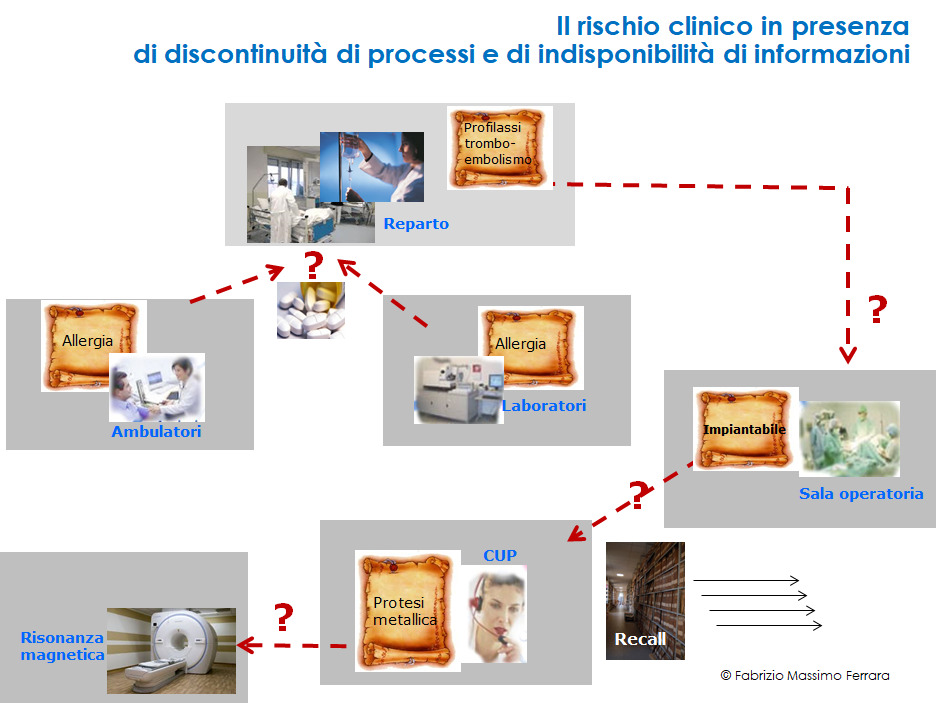
Figura 2. La non disponibilità di tutti i dati necessari aumenta i fattori di rischio
Questa integrazione e disponibilità dei dati costituisce un requisito sempre più indispensabile, non solo ai fini della prevenzione del rischio clinico, ma anche per assicurare la qualità delle cure sia nel contesto della singola azienda che nei percorsi sul territorio, per gestire in modo efficiente ed economico le risorse, per proteggere i dati personali, per trarre beneficio dai big-data, per supportare la ricerca, etc..
La criticità degli scenari attuali
I sistemi informativi sanitari si sono in massima parte evoluti nel tempo secondo una logica “a silos” mediante aggregazione di applicazioni dedicate alle esigenze di singoli settori organizzativi e/o specialità cliniche. Ogni applicazione gestisce un sottoinsieme dell’intero patrimonio informativo aziendale, anche replicato rispetto a quanto presente in altri settori, secondo modelli e tecnologie proprietarie, non direttamente accessibili all’azienda e con scarse possibilità di sincronizzazione reciproca. La loro struttura, come schematizzato in figura 3, non favorisce, anzi rappresenta spesso un ostacolo rispetto alle esigenze di integrazione e condivisione dei dati.
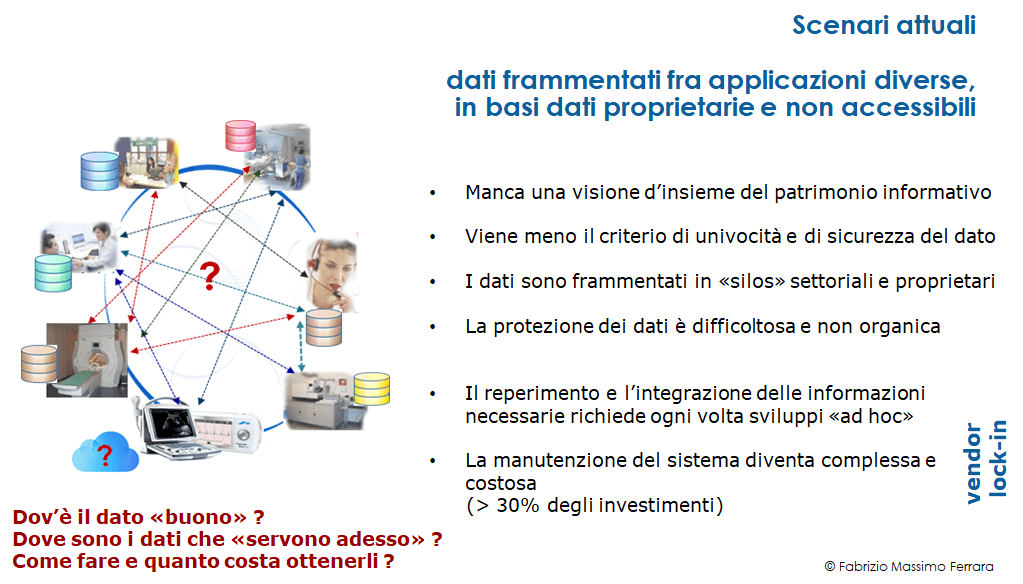
Figura 3 – La struttura “a silos” dei sistemi informativi
Questo determina conseguenze non soltanto dal punto di vista del rischio clinico, ma anche sotto il profilo normativo, sotto quello economico-organizzativo e sotto quello della ricerca e della prevenzione. La frammentazione dei dati in contesti diversi, anche in cloud e gestiti da fornitori diversi, rende infatti difficile, se non impossibile:
- dal punto di vista clinico
presentare un quadro complessivo dello stato di salute del paziente per assicurare la massima fondatezza delle decisioni cliniche e per attivare quei meccanismi di monitoraggio e quelle segnalazioni di alert riscontrabili dalla correlazione di diverse informazioni (es. co-morbilità, allergie, …)
- dal punto di vista economico e della continuità del percorso di cura
assicurare la continuità dei processi, evitando trascrizioni manuali, hand-over verbali o cartacei, pianificare ed ottimizzare le risorse necessarie al controllo di gestione, specialmente in un contesto distribuito e di collaborazione sul territorio
- dal punto di vista della protezione dei dati
adempiere a tutte le disposizioni del Regolamento, non solo in termini di criteri e livelli uniformi per la sicurezza ed il controllo sugli accessi e sull’utilizzo dei dati personali, ma anche relativamente al diritto dell’interessato all’ottenimento ed alla trasportabilità dei propri dati
- dal punto di vista della prevenzione e della ricerca
disporre di un patrimonio informativo, coerente ed il più ampio possibile, necessario per eseguire -nel rispetto della normativa- analisi statistiche, epidemiologiche e di ricerca
Non vanno inoltre sottovalutate le implicazioni in termini di dipendenza dell’azienda dai fornitori, ai quali bisogna rivolgersi -con i conseguenti oneri in termini di tempi e di costi- ogni qual volta sia necessaria l’acquisizione di dati di interesse, gestiti all’interno delle applicazioni, secondo strutture non pubbliche e non stabili nel tempo. Con il limite, comunque, che tali esportazioni vanno a supportare esigenze contingenti, ma non contribuiscono alla capitalizzazione in un patrimonio di dati stabile ed usabile nel tempo per vari scopi.
A livello più generale, questa dipendenza determina le cosiddette situazioni di “vendor lock-in”, con le conseguenti difficolta dell’organizzazione di essere realmente indipendente rispetto ai fornitori anche in fase di gara e di evoluzione del sistema informativo, di rilevanza anche sotto il profilo giuridico. A questo proposito vale ricordare le “Linee guida 8” dell’Autorità Nazionale Anticorruzione ([4]), che indicano espressamente come causa di infungibilità “i costi della migrazione di dati (e documenti) informatici” e raccomandano quanto previsto dal “Quadro europeo di interoperabilità – Strategia di attuazione” che, fra i principi fondamentali, esplicita che:
- “tutti i dati pubblici dovrebbero essere liberamente accessibili per l’utilizzo e il riutilizzo da parte di terzi”
- “le pubbliche amministrazioni devono rendere l’accesso e il riutilizzo dei loro servizi pubblici e dati indipendente da qualsiasi tecnologia o prodotto specifici”.
L’evoluzione dei modelli di cura e assistenziali verso forme sempre maggiormente rivolte alla deospedalizzazione ed alla collaborazione di diversi attori nell’ambito di percorsi, composti di diversi episodi e forme di interazione incentrate sulla persona, insieme all’evoluzione tecnologica (inclusa la telemedicina ed i dispositivi, IoT) ed al proliferare di prodotti e soluzioni specializzati per specifiche esigenze, porta ad aumentare sempre di più questa frammentazione dei dati, che diventano sempre più settoriali e circoscritti ad attività specifiche e registrati secondo tecnologie diverse e con modelli sintattici e semantici diversi, quasi sempre proprietari.
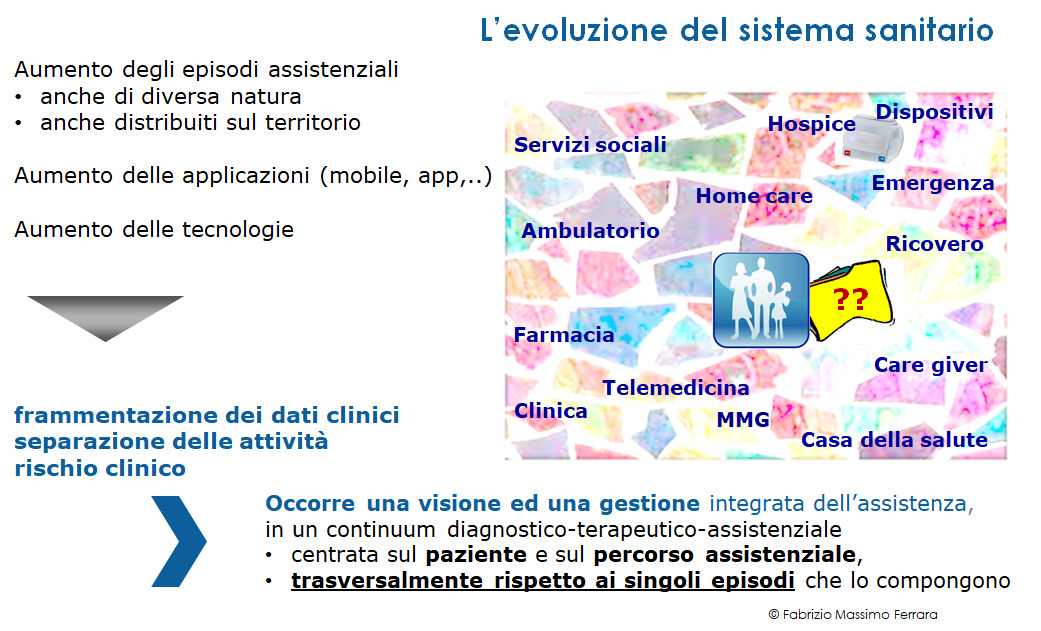
Figura 4 – L’evoluzione del sistema sanitario e la conseguente crescente frammentazione dei dati
Uno studio IDC stima la crescita del volume dei dati sanitari in circa il 48% annuo, per arrivare nel 2020 a oltre 2.300 exabyte di dati raccolti, ci cui il 16% provenienti da dispositivi (Figura 5)

Figura 5 – L’incremento del volume dei dati
In definitiva, l’innovazione digitale, insieme all’evoluzione dei modelli assistenziali, rischia di diventare un freno ed una criticità verso quegli obiettivi di continuità del percorso e di centralità della persona verso cui sta tendendo il sistema sanitario.
In mancanza di una strategia finalizzata alla integrazione ed al governo dei dati, questo scenario tenderà sempre più a divergere, in parallelo alla crescente rilevanza della sanità digitale e dei modelli assistenziali basati su percorsi, su reti di collaborazione sul territorio, su telemedicina.
Una strategia per l’evoluzione
Per l’individuazione di una tale strategia sono opportune alcune considerazioni preliminari:
a) È innanzitutto necessario preservare la possibilità di integrare nel sistema informativo applicazioni diverse, fornite da fornitori diversi e basate anche su tecnologie diverse, selezionabili senza condizionamenti tecnici e/o commerciali, ma in funzione della sola adeguatezza della soluzione rispetto alle esigenze cliniche ed organizzative ed della convenienza economica.
Non solo per quanto riguarda i costi e la complessità attuativa, non è infatti ipotizzabile l’evoluzione del sistema informativo verso soluzioni monolitiche di un unico fornitore. Le esperienze effettuate in questo senso negli ultimi decenni hanno dimostrato come un unico sistema monolitico (tipo ERP) possa semmai garantire il supporto organizzativo ai processi principali ma non consenta -anche per la molteplicità e la rapidità delle evoluzioni cliniche e tecnologiche e la diversità dei modelli assistenziali- di essere adeguato in tutte le situazioni.
b) Analogamente, è necessario un approccio “non invasivo”, tale cioè da non richiedere modifiche alle applicazioni già esistenti e funzionanti nell’azienda, la cui variazione determinerebbe tempi e costi ulteriori. Approccio al tempo stesso flessibile e graduale, tale cioè da poter essere implementato secondo le priorità, le esigenze e le risorse dell’azienda, consentendo una capitalizzazione continua su quanto man mano realizzato.
c) Infine, ma forse per primo dal punto di vista strategico, è necessario che il patrimonio informativo aziendale integrato sia organizzato secondo un modello pubblico e stabile nel tempo e secondo strumenti non proprietari (preferibilmente open-source), in modo da garantire realmente all’azienda la totale proprietà sui propri dati e la possibilità di usare gli stessi (o di concederne l’accesso alle applicazioni) come e quando necessario, senza condizionamenti di sorta -con i conseguenti tempi e costi- rispetto a specifici fornitori.
In definitiva, quindi, una tale strategia per l’integrazione del patrimonio informativo aziendale non deve essere alternativa, ma complementare rispetto al requisito di interoperabilità dei sistemi per il supporto ai singoli processi (figura 6). Si può delineare un approccio simile a quello che viene utilizzato con il datawarehouse nel contesto amministrativo. Ovvero affiancare agli scenari esistenti una base dati, strutturata secondo un opportuno modello, nella quale far confluire i dati sanitari ed organizzativi prodotti dalle diverse applicazioni nel normale supporto alle operatività giornaliere.
Il tutto agendo trasparentemente sulle basi dati delle applicazioni esistenti (mediante strumenti e meccanismi già disponibili e/o implementati una volta soltanto) e lasciando inalterate le funzionalità esistenti ed i loro meccanismi di interazione. Senza quindi determinare costi e conseguenze sulle operatività giornaliere.
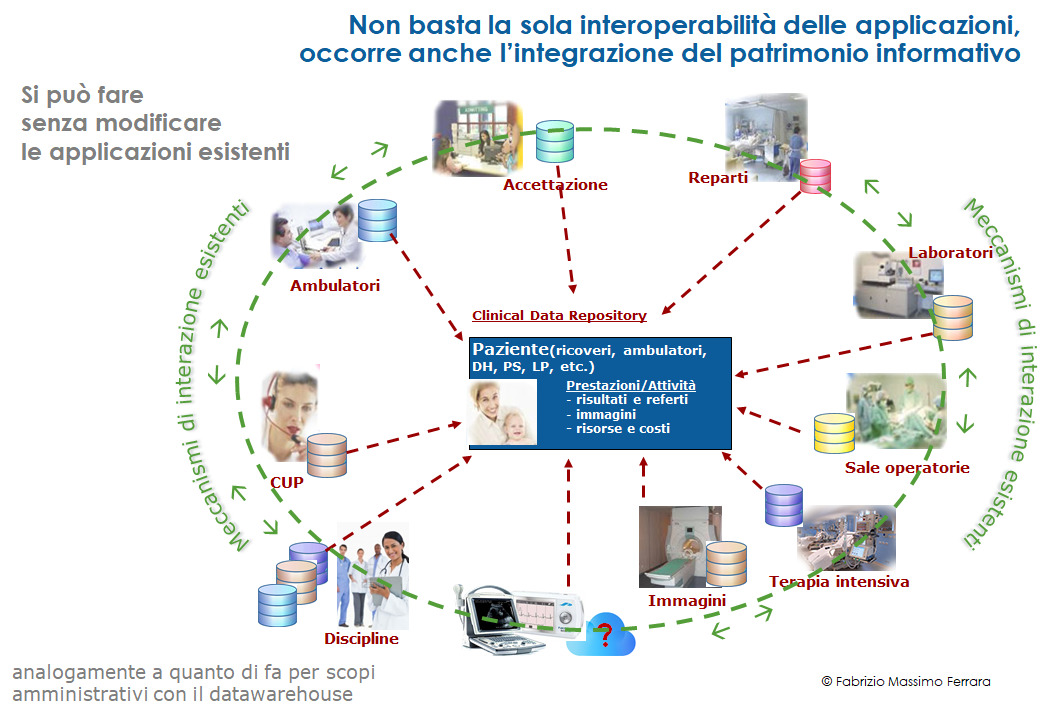
Figura 6 – L’integrazione del patrimonio informativo insieme alla interoperabilità delle applicazioni
Questa base dati (nel seguito “Clinical Data Repository”, figura 7) dovrà essere strutturata secondo un modello opportuno, incentrato sul paziente e sul suo percorso, trasversalmente rispetto agli episodi assistenziali. Dovrà tener traccia degli episodi, delle prestazioni erogate (con le relative risorse utilizzate) e dei dati clinici, intesi non solo in termini di documenti (anche strutturati e firmati con validità legale), ma soprattutto in termini di dati elementari in grado di essere analizzati, comparati ed associati individualmente secondo le esigenze dello specifico trattamento, anche con l’evidenziazione automatica di allarmi e situazioni di rilevanza per il medico.
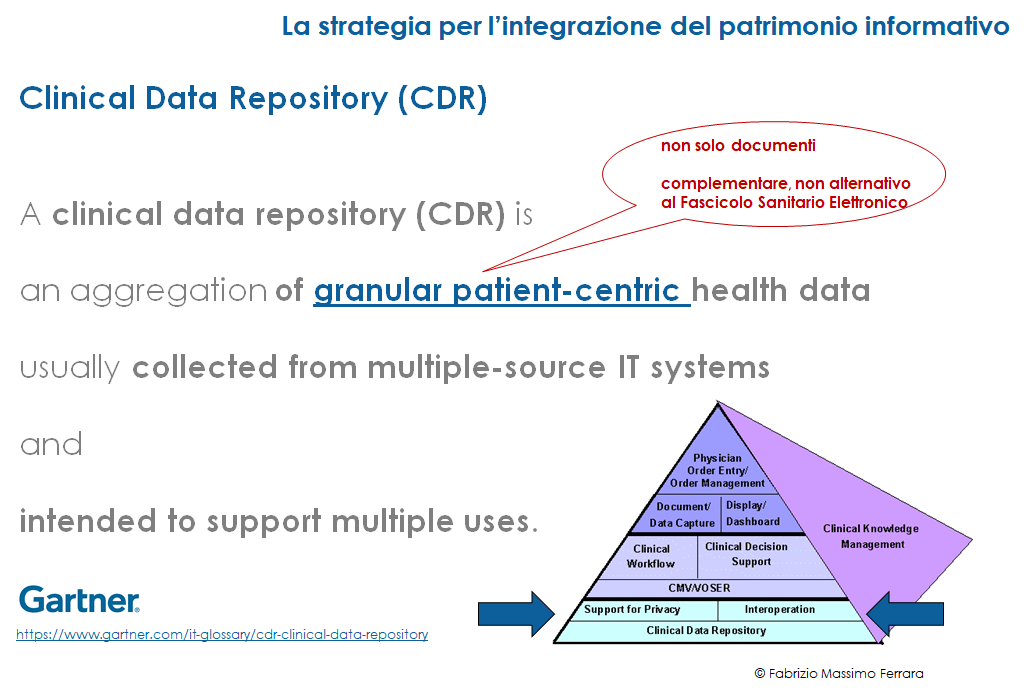
Figura 7 – Il Clinical Data Repository
Per quanto riguarda la struttura del modello dati, si può ricordare che esiste uno standard internazionale (ISO 12967:2009 “Health Informatics – Service Architecture”) che definisce per l’appunto un modello dati finalizzato a questo scopo, ormai largamente utilizzato in diversi contesti locali e territoriali a livello internazionale, e del quale sono disponibili implementazioni open-source (uno, ad esempio implementato dal Laboratorio ALTEMS sui Sistemi Informativi Sanitari) operanti con i più diffusi sistemi di gestione di basi di dati. La definizione del repository, pertanto, può risultare abbastanza agevole partendo da quanto definito nello standard e -se necessario- estendendolo per far fronte ad ulteriori requisiti specifici.

Figura 8 – Requisito essenziale per il Clinical Data Repository, standard e non proprietario
La Community per il governo dei dati
Alla luce di queste considerazioni, nella seconda metà del 2019 è stata avviata l’iniziativa di una “Community per il governo dei dati” (www.dati-sanita.it , figura 9) con la missione di promuovere e supportare la definizione e la condivisione di ricerche, di metodologie e di strumenti open-source non proprietari per l’integrazione, la protezione, la sicurezza e l’utilizzo dei dati, sia all’interno delle singole aziende sanitarie che nei contesti di collaborazione per la continuità di cura sul territorio.
La Community è aperta alla collaborazione di istituzioni, aziende sanitarie, enti di ricerca, industrie ed è promossa e coordinata da
- la Fondazione per la Sicurezza in Sanità
- la Direzione Generale per la Vigilanza e la Sicurezza delle Cure del Ministero della Salute
- il Dipartimento di Ingegneria Informatica, Automatica e Gestionale “A. Ruberti” dell’Università Sapienza
- l’ALTEMS dell’ Università Cattolica del Sacro Cuore
- l’Osservatorio Innovazione Digitale in Sanità del Politecnico Milano
- l’ Italian Community di HIMSS
Come termine di riferimento per un Clinical Data Repository comune e non proprietario è stato adottato il modello definito nello standard UNI-CEN-ISO 12967:2009 “Health Informatics Service Architecture”, per la cui implementazione sono stati realizzati e resi disponibili componenti software open-source omogenei per i principali sistemi di gestione di basi di dati.
Quale primo caso di best-practice all’interno della Community, vale citare la ASL di Foggia, che ha adottato il CDR standard e, nell’ambito bando recentemente pubblicato per l’evoluzione dell’intero sistema informativo aziendale, ha definito il requisito e le specifiche per il collegamento di tutte le applicazioni con il CDR, in modo da alimentare ed utilizzare il patrimonio informativo aziendale integrato.

- Ferrara, “ICT e HTA: il ruolo dell’HTA nella valutazione dei sistemi informativi sanitari”; IX congresso SIHTA, Ottobre 2016 ↑
- Ferrara F.M., Cicchetti A., “I sistemi informativi e l’Health Technology Assessment”, Progettare per la Sanità, Novembre 2016 ↑
- Ferrara F.M., Pillon S. “Medicina Digitale – Sicurezza per il medico e per il paziente”, Progettare per la Sanità, Settembre 2016 ↑
- delibera numero 950 del 13 settembre 2017 ↑

























